【前面的话】Java中的Stream于1.8版本析出,平时项目中也有用到,今天就系统的来实践一下。下面借用重庆力帆队伍中我个人比较喜欢的球员来操作一波,队员的年龄为了便于展示某些api做了调整,请不要太认真哦。
壹. Stream理解
在java中我们称Stream为『流』,我们经常会用流去对集合进行一些流水线的操作。stream就像工厂一样,只需要把集合、命令还有一些参数灌输到流水线中去,就可以加工成得出想要的结果。这样的流水线能大大简洁代码,减少操作。给我个人的感觉类似JavaScript中的链式函数。
贰. Stream流程
原集合 —> 流 —> 各种操作(过滤、分组、统计) —> 终端操作Stream流的操作流程一般都是这样的,先将集合转为流,然后经过各种操作,比如过滤、筛选、分组、计算。最后的终端操作,就是转化成我们想要的数据,这个数据的形式一般还是集合,有时也会按照需求输出count计数。下文会一一举例。
叁. API实践
首先,定义一个用户对象,包含姓名、年龄、id三个成员变量:
package com.eelve.training.entity;import lombok.*;import javax.persistence.*;/** * @ClassName User * @Description TDO * @Author zhao.zhilue * @Date 2019/6/28 15:21 * @Version 1.0 **/@Data@Entity@Table(name = "user")@ToString@NoArgsConstructor@AllArgsConstructor@EqualsAndHashCode(exclude={"id","name"})public class User implements Comparable<User>{ @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "id") private Integer id; /** * Link name. */ @Column(name = "name", columnDefinition = "varchar(255) not null") private String name; @Column(name = "age") private Integer age; public User(String name, Integer age) { this.name = name; this.age = age; } @Override public int compareTo(User o) { return age.compareTo(o.getAge()); }}然后在数据库中插入测试数据,见下图: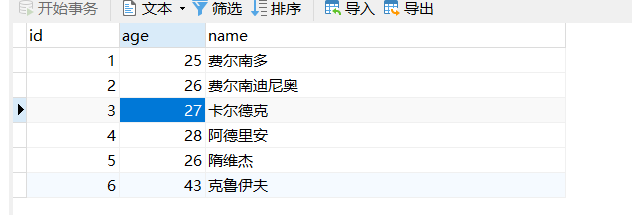
3.1过滤
1)filter 过滤(T-> boolean)
假如我们要实现过滤出40岁以下的队员,我们可以这样来实现:
@Test public void testUserStreamFilter(){ List<User> userList = userMapper.getALL(); List<User> resultList = userList.stream().filter(user -> user.getAge() <= 40).collect(Collectors.toList()); for (User user : resultList){ System.out.println(user.toString()); } }filter里面,->箭头后面跟着的是一个boolean值,可以写任何的过滤条件,就相当于sql中where后面的东西,换句话说,能用sql实现的功能这里都可以实现
执行结果为:
User(id=1, name=费尔南多, age=25)User(id=2, name=费尔南迪尼奥, age=26)User(id=3, name=卡尔德克, age=27)User(id=4, name=阿德里安, age=28)User(id=5, name=隋维杰, age=26)2)distinct 去重
其用法和sql中的使用类似,假如我们要实现过去除用重复年龄的队员,我们可以这样来实现:
@Test public void testUserDistinct(){ List<User> userList = userMapper.getALL(); List<User> resultList = userList.stream().distinct().collect(Collectors.toList()); for (User user : resultList){ System.out.println(user.toString()); } }执行结果为:
User(id=1, name=费尔南多, age=25)User(id=2, name=费尔南迪尼奥, age=26)User(id=3, name=卡尔德克, age=27)User(id=4, name=阿德里安, age=28)User(id=6, name=克鲁伊夫, age=43)3)sorted排序
如果流中的元素的类实现了 Comparable 接口,即有自己的排序规则,那么可以直接调用 sorted() 方法对元素进行排序,如:
@Override public int compareTo(User o) { return age.compareTo(o.getAge()); }@Test public void testUserStreamSorted(){ List<User> userList = userMapper.getALL(); List<User> resultList = userList.stream().sorted().collect(Collectors.toList()); for (User user : resultList){ System.out.println(user.toString()); } }反之, 需要调用 sorted((T, T) -> int) 实现 Comparator 接口。
@Test public void testUserStreamSortedWithComparator(){ List<User> userList = userMapper.getALL(); List<User> resultList = userList.stream().sorted(Comparator.comparingInt(User::getAge)).collect(Collectors.toList()); for (User user : resultList){ System.out.println(user.toString()); } }执行结果为:
User(id=1, name=费尔南多, age=25)User(id=2, name=费尔南迪尼奥, age=26)User(id=5, name=隋维杰, age=26)User(id=3, name=卡尔德克, age=27)User(id=4, name=阿德里安, age=28)User(id=6, name=克鲁伊夫, age=43)4)limit() 返回前n个元素
如果想知道队伍中年龄最小的就可以使用下面来实现:
@Test public void testUserStreamLimit(){ List<User> userList = userMapper.getALL(); List<User> resultList = userList.stream().limit(2).collect(Collectors.toList()); for (User user : resultList){ System.out.println(user.toString()); } }执行结果为:
User(id=1, name=费尔南多, age=25)User(id=2, name=费尔南迪尼奥, age=26)5)skip
它的用法和limit正好相反,是去除前面几个元素。
假如我们要去除前面两个元素就可以使用下面的方法来实现:
@Test public void testUserStreamSkip(){ List<User> userList = userMapper.getALL(); List<User> resultList = userList.stream().skip(2).collect(Collectors.toList()); for (User user : resultList){ System.out.println(user.toString()); } }执行结果为:
User(id=3, name=卡尔德克, age=27)User(id=4, name=阿德里安, age=28)User(id=5, name=隋维杰, age=26)User(id=6, name=克鲁伊夫, age=43)6)组合使用
以上的过滤函数物品们可以组合来使用来实现我们具体的需求,示例代码如下:
@Test public void testUserStreamSortLimit(){ List<User> userList = userMapper.getALL(); List<User> resultList = userList.stream().sorted().limit(5).collect(Collectors.toList()); for (User user : resultList){ System.out.println(user.toString()); } }这样我们就可以得到先排序后限制的结果:
User(id=1, name=费尔南多, age=25)User(id=2, name=费尔南迪尼奥, age=26)User(id=5, name=隋维杰, age=26)User(id=3, name=卡尔德克, age=27)User(id=4, name=阿德里安, age=28)3.2 映射
1)map(T->R)
map是将T类型的数据转为R类型的数据,比如我们想要设置一个新的list,存储用户所有的城市信息。
@Test public void testUserStreamMap(){ List<User> userList = userMapper.getALL(); List<Integer> resultList = userList.stream().map(User::getAge).distinct().collect(Collectors.toList()); System.out.println(resultList.toString()); }这样我们可以得到所有年龄的样本,执行结果为:
[25, 26, 27, 28, 43]2)flatMap(T -> Stream)
将流中的每一个元素 T 映射为一个流,再把每一个流连接成为一个流。
@Test public void testStreamMap(){ List<String> habitsList = new ArrayList<>(); habitsList.add("唱歌,听歌"); habitsList.add("羽毛球,足球,登山"); habitsList = habitsList.stream().map(s -> s.split(",")).flatMap(Arrays::stream).collect(Collectors.toList()); System.out.println(habitsList); }执行结果为:
[唱歌, 听歌, 羽毛球, 足球, 登山]这里原集合中的数据由逗号分割,使用split进行拆分后,得到的是Stream<String[]>,字符串数组组成的流,要使用flatMap的Arrays::stream,将Stream<String[]>转为Stream
3.3 查找
1)allMatch(T->boolean)
检测是否全部满足参数行为,假如我们要检测是不是所有队员都是U21的球员:
@Test public void testUserStreamAllMatch(){ List<User> userList = userMapper.getALL(); boolean isNotU21 = userList.stream().allMatch(user -> user.getAge() >= 21); System.out.println("是否都不是U21球员:" + isNotU21); }执行结果为:
是否都不是U21球员:true2)anyMatch(T->boolean)
检测是否有任意元素满足给定的条件,比如,想知道是否有26岁的球员:
@Test public void testUserStreamAnyMatch(){ List<User> userList = userMapper.getALL(); boolean isAgeU26 = userList.stream().anyMatch(user -> user.getAge() == 26); System.out.println("是否有26岁的球员:" + isAgeU26); }执行结果为:
是否有26岁的球员:true3)noneMatch(T -> boolean)
流中是否有元素匹配给定的 T -> boolean 条件。比如我们要检测是否含有U18的队员:
@Test public void testUserStreamNoneMatch(){ List<User> userList = userMapper.getALL(); boolean isNotU18 = userList.stream().noneMatch(user -> user.getAge() <= 18); System.out.println("是否都不是U18球员:" + isNotU18); }执行结果为:
是否都不是U18球员:true说明没有U18的队员。
4)findFirst( ):找到第一个元素
@Test public void testUserFindFirst(){ List<User> userList = userMapper.getALL(); Optional<User> firstUser = userList.stream().sorted().findFirst(); System.out.println(firstUser.toString()); }执行结果为:
Optional[User(id=1, name=费尔南多, age=25)]5)findAny():找到任意一个元素
@Test public void testUserFindAny(){ List<User> userList = userMapper.getALL(); Optional<User> anytUser = userList.parallelStream().sorted().findAny(); System.out.println(anytUser.toString()); }执行结果为:
Optional[User(id=2, name=费尔南迪尼奥, age=26)]3.4 归纳计算
1)求队员的总人数
@Test public void testUserCount(){ List<User> userList = userMapper.getALL(); long totalAge = userList.stream().collect(Collectors.counting()); System.out.println("队员人数为:" + totalAge); }执行结果为:
队员人数为:62)得到某一属性的最大最小值
@Test public void testUserMaxAndMin(){ List<User> userList = userMapper.getALL(); Optional<User> userMaxAge = userList.stream().collect(Collectors.maxBy(Comparator.comparing(User::getAge))); System.out.println("年龄最大的队员为:" + userMaxAge.toString()); Optional<User> userMinAge = userList.stream().collect(Collectors.minBy(Comparator.comparing(User::getAge))); System.out.println("年龄最小的队员为:" + userMinAge.toString()); }执行结果为:
年龄最大的队员为:Optional[User(id=6, name=克鲁伊夫, age=43)]年龄最小的队员为:Optional[User(id=1, name=费尔南多, age=25)]3)求年龄总和是多少
@Test public void testUserSummingInt(){ List<User> userList = userMapper.getALL(); int totalAge = userList.stream().collect(Collectors.summingInt(User::getAge)); System.out.println("年龄总和为:" + totalAge); }执行结果为:
年龄总和为:175我们经常会用BigDecimal来记录金钱,假设想得到BigDecimal的总和:
// 获得列表对象金额, 使用reduce聚合函数,实现累加器
BigDecimal sum = myList.stream() .map(User::getMoney)
.reduce(BigDecimal.ZERO,BigDecimal::add);
4)求年龄平均值
@Test public void testUserAveragingInt(){ List<User> userList = userMapper.getALL(); Double totalAge = userList.stream().collect(Collectors.averagingInt(User::getAge)); System.out.println("平均年龄为:" + totalAge); }执行结果为:
平均年龄为:29.1666666666666685)一次性得到元素的个数、总和、最大值、最小值
@Test public void testUserSummarizingInt(){ List<User> userList = userMapper.getALL(); IntSummaryStatistics statistics = userList.stream().collect(Collectors.summarizingInt(User::getAge)); System.out.println("年龄的统计结果为:" + statistics ); }执行结果为:
年龄的统计结果为:IntSummaryStatistics{count=6, sum=175, min=25, average=29.166667, max=43}6)字符串拼接
要将队员的姓名连成一个字符串并用逗号分割。
@Test public void testUserJoining(){ List<User> userList = userMapper.getALL(); String name = userList.stream().map(User::getName).collect(Collectors.joining(",")); System.out.println("所有的队员名字:" + name ); }执行结果为:
所有的队员名字:费尔南多,费尔南迪尼奥,卡尔德克,阿德里安,隋维杰,克鲁伊夫3.5 分组
在数据库操作中,我们经常通过GROUP BY关键字对查询到的数据进行分组,java8的流式处理也提供了分组的功能。使用Collectors.groupingBy来进行分组。
1)可以根据队员的年龄进行分组
@Test public void testUserGroupingBy(){ List<User> userList = userMapper.getALL(); Map<Integer, List<User>> ageMap = userList.stream().collect(Collectors.groupingBy(User::getAge)); for (Map.Entry<Integer,List<User>> entry :ageMap.entrySet()){ System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue()); } }执行结果为:
key= 25 and value= [User(id=1, name=费尔南多, age=25)]key= 26 and value= [User(id=2, name=费尔南迪尼奥, age=26), User(id=5, name=隋维杰, age=26)]key= 43 and value= [User(id=6, name=克鲁伊夫, age=43)]key= 27 and value= [User(id=3, name=卡尔德克, age=27)]key= 28 and value= [User(id=4, name=阿德里安, age=28)]结果是一个map,key为不重复的年龄,value为属于该年龄的队员列表。已经实现了分组。另外我们还可以继续分组得到两次分组的结果。
2)如果仅仅想统计各年龄的队员个数是多少,并不需要对应的list
按年龄分组并统计人数:
@Test public void testUserGroupingByCount(){ List<User> userList = userMapper.getALL(); Map<Integer,Long> ageMap = userList.stream().collect(Collectors.groupingBy(User::getAge,Collectors.counting())); for (Map.Entry<Integer,Long> entry :ageMap.entrySet()){ System.out.println("队员中" + entry.getKey() + "岁的队员人数为:" + entry.getValue()); } }执行结果为:
队员中25岁的队员人数为:1队员中26岁的队员人数为:2队员中43岁的队员人数为:1队员中27岁的队员人数为:1队员中28岁的队员人数为:13)partitioningBy 分区
分区与分组的区别在于,分区是按照 true 和 false 来分的,因此partitioningBy 接受的参数的 lambda 也是 T -> boolean
@Test public void testUserPartitioningBy (){ List<User> userList = userMapper.getALL(); Map<Boolean,List<User>> partitioningByMap = userList.stream().collect(partitioningBy(user -> user.getAge() >= 30)); for (Map.Entry<Boolean,List<User>> entry :partitioningByMap.entrySet()){ System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue()); } }执行结果为:
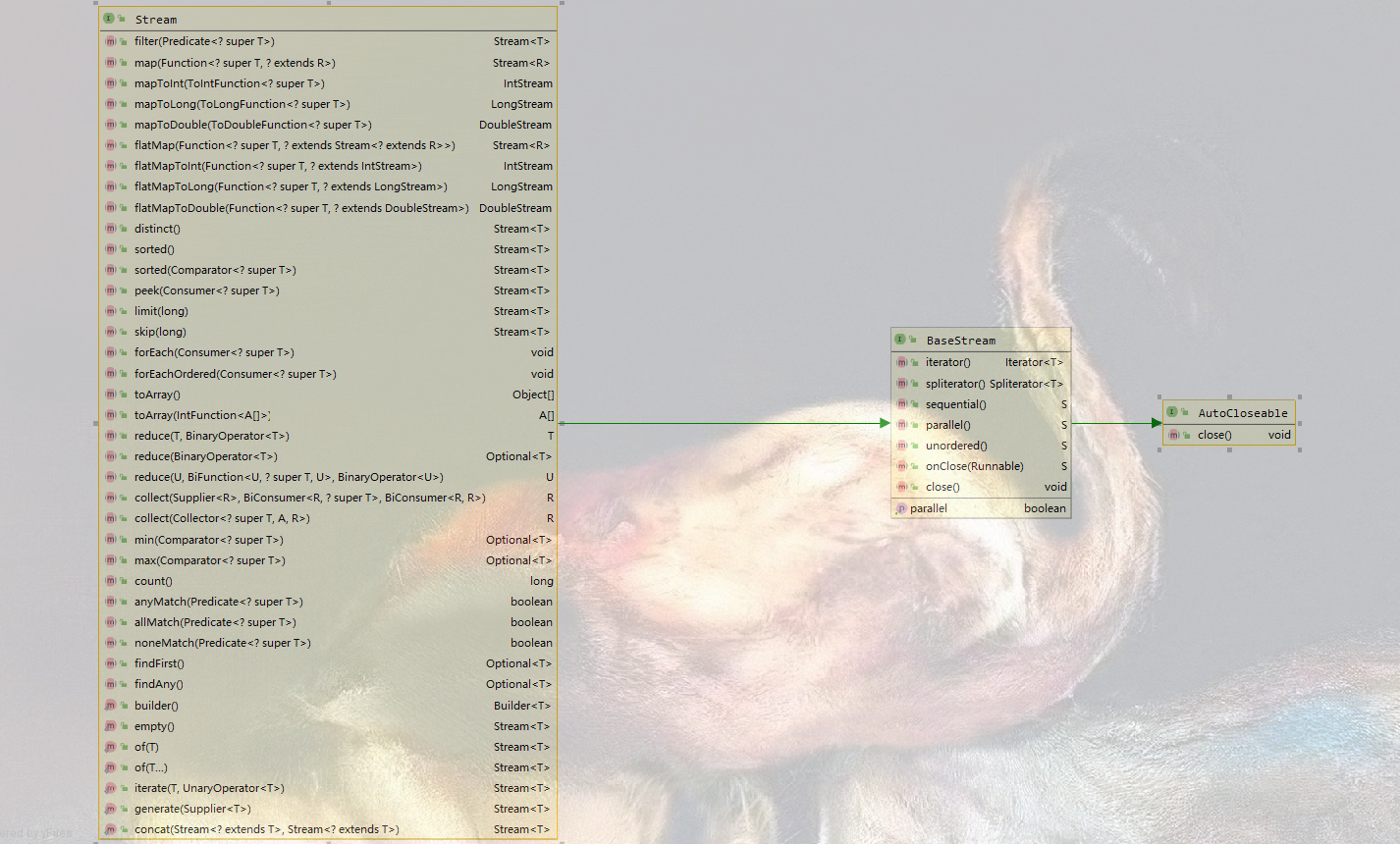
key= false and value= [User(id=1, name=费尔南多, age=25), User(id=2, name=费尔南迪尼奥, age=26), User(id=3, name=卡尔德克, age=27), User(id=4, name=阿德里安, age=28), User(id=5, name=隋维杰, age=26)]key= true and value= [User(id=6, name=克鲁伊夫, age=43)]【写在后面的话】留下stream的类实现的方法和依赖图,前面的实践也只是挑选了几个比较常用的Api。
原文转载:http://www.shaoqun.com/a/504749.html
tenso:https://www.ikjzd.com/w/1552.html
blackbird:https://www.ikjzd.com/w/950
【前面的话】Java中的Stream于1.8版本析出,平时项目中也有用到,今天就系统的来实践一下。下面借用重庆力帆队伍中我个人比较喜欢的球员来操作一波,队员的年龄为了便于展示某些api做了调整,请不要太认真哦。壹.Stream理解在java中我们称Stream为『流』,我们经常会用流去对集合进行一些流水线的操作。stream就像工厂一样,只需要把集合、命令还有一些参数灌输到流水线中去,就可以加工成
拍怕:拍怕
easybuy:easybuy
2019跨境大卖日历+亚马逊开店指导手册:2019跨境大卖日历+亚马逊开店指导手册
亚马逊开店前期转化少吗?应该怎样提高产品销量?:亚马逊开店前期转化少吗?应该怎样提高产品销量?
暑假去冰岛旅游前需要知道些什么:暑假去冰岛旅游前需要知道些什么
No comments:
Post a Comment