编译过程
编译目标
目标:把源代码变成目标代码
1.如果源代码在操作系统上运行:目标代码就是"汇编代码"。再通过汇编和链接的过程形成可执行文件,然后通过加载器加载到操作系统执行。
2.如果源代码在虚拟机(解释器)上运行:目标代码就是"解释器可以理解的中间形式的代码",比如字节码(中间代码)IR、AST语法树。
编译过程可以分为这几个阶段,每个阶段做了一定的任务,层级的让下一个阶段进行。
词法分析
编译器读入源代码,经过词法分析器识别出Token,把字符串转换成一个个Token。
Token的类型包括:关键字、标识符、字面量、操作符、界符等
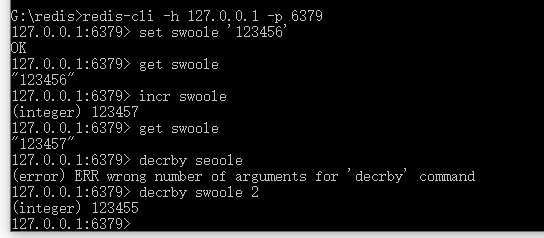
比如下面的C语言代码源文件,经过词法分析器识别出的token有:int、foo、a、b、=、+、return、(){}等token
int foo(int a){ int b = a + 3; return b;}为什么要这样做呢,把代码里的单词进行分类,编译器后面的阶段不就更好处理理解代码了嘛!
语法分析
每一个程序代码,实际上可以通过树这种结构表现出其语法规则。
语法分析阶段把Token串,转换成一个体现语法规则的、树状数据结构,即抽象语法树AST。
AST树反映了程序的语法结构。
比如下面对应的一段C语言代码,对应的AST抽象语法树如下所示:
int foo(int a){ int b = a + 3; return b;}
AST抽象语法树
AST树长成什么样,由语法的结构有关。
比如 上面C语言代码中对函数的语法定义如下:语法分析器就按照语法定义进行解析,就是从上到下匹配的过程。
也就是先匹配function的规则,匹配函数类型type、函数名name、函数参数parameters、函数体
当匹配函数参数时,就去匹配parameters的规则
当匹配函数体时,函数体由一个个语句组成,就去匹配各个语句stmt的规则。
function := type name parameters functionBodyparameters:= parameter* functionBody:= stmt returnStatement生成 AST 以后,程序的语法结构就很清晰了,但这棵树到底代表了什么意思,我们目前仍然不能完全确定,要在语义分析阶段确定。
为什么要把程序转换成AST这么一颗树,因为编译器不像人能直接理解语句的含义,AST树更有结构性,后续阶段可以针对这颗树做各种分析!
语义分析
语义分析阶段的任务:理解语义,语句要做什么。
比如+号要执行加法、=号要执行赋值、for结构要去实现循环、if结构实现判断。
所以语义阶段要做的内容有:上下文分析(包括引用消解、类型分析与检查等)
引用消解:找到变量所在的作用域,一个变量作用范围属于全局还是局部。
类型识别:比如执行a+3,需要识别出变量a的类型,因为浮点数和整型执行不一样,要执行不同的运算方式。
类型检查:比如int b = a + 3,是否可以进行定义赋值。等号右边的表达式必须返回一个整型的数据、或则能够自动转换成整型的数据,才能够对类型为整型的变量b进行复制。
比如之前的一段C语言代码,经过语义分析后获得的信息(引用消解信息、类型信息),可以在AST上进行标注,形成下面的"带有标注的语法树",让编译器更好的理解程序的语义。
也会将这些上下文信息存入"符号表"结构中,便于各阶段查询上下文信息。
符号表是有层次的结构:我们只需要逐级向上查找就能找到变量、函数等的信息(作用域、类型等)
接下来就可以 解释执行:实现一门解释型的语言
Tip:编译型语言需要生成目标代码,而解释性语言只需要解释器去执行语义就可以了。
实现AST的解释器:在语法分析后有了程序的抽象语法树,在语义分析后有了"带有标注的AST"和符号表后,就可以深度优先遍历AST,并且一边遍历一边执行结点的语义规则。整个遍历的过程就是执行代码的过程。
举一个解释执行的例子,比如执行下面的语义:
- 遇到语法树中的add "+"节点:把两个子节点的值进行相加,作为"+"节点的值。
- 遇到语法树中的变量节点(右值):就取出变量的值。
- 遇到字面量比如数字2:返回这个字面量代表的数值2。
中间代码生成
在编译前端完成后(编译器已经理解了词法和语义),编译器可以直接解释执行、或则直接生成目标代码。对于不同架构的CPU,还需要生成不同的汇编代码,如果对每一种汇编代码做优化就很繁琐了。所以我们需要增加一个环节:生成中间代码IR,统一优化后中间代码,再去将中间代码生成目标代码。
中间代码IR的两个用途:解释执行 、代码优化
解释执行:解释型语言,比如Python和Java,生成IR后就能直接执行了,也就是前面举出的例子。
优化代码:比如LLVM等工具;在生成代码后需要做大量的优化工作,而很多优化工作没必要使用汇编代码来做(因为不同CPU体系的汇编语言不同),而可以基于IR用统一的算法来完成,降低编译器适配不同CPU的复杂性。
代码优化
一种方案:基于基本块作代码优化
分类:本地优化、全局优化、过程间优化
本地优化:可用表达式分析、活跃性分析
全局优化:基于控制流图CFG作优化。
控制流图CFG :是一种有向图,它体现了基本块之前的指令流转关系,如果从BLOCK1的最后一条指令是跳转到 BLOCK2, 就连一条边,如果通过分析 CFG,发现某个变量在其他地方没有被使用,就可以把这个变量所在代码行删除。
过程间优化:跨越函数的优化,多个函数间作优化
优化案例:
代数优化:
比如删除"x:=x+0 ",乘法优化掉"x:=x乘以0" 可以简化成"x:=0",乘法优化成移位运算:"x:=x*8"可以优化成"x:=x<<3"。
常数折叠:
对常数的运算可以在编译时计算,比如 "x:= 20 乘以 3 "可以优化成"x:=60"
删除公共子表达式:作"可用表达式分析"
x := a + by := a + b //优化成y := x拷贝传播:作"可用表达式分析"
x := a + by := xz := 2 * y //优化成z:= 2 * x常数传播:
x := 20y := 10z := x + y//优化成z := 30死代码删除:作变量的"活跃性分析"
活跃性分析(优化删除死代码,没用到的变量) 数据流分析:使用"半格理论"解决多路径的V值计算集合问题,不在代码下面集合的变量就是死代码。
目标代码生成
目标代码生成,也就是生成虚拟机执行的字节码,或则操作系统执行的汇编代码
代码生成的过程,其实很简单,就是将中间代码IR逐个翻译成想要的汇编的代码
那么目标代码生成阶段的任务就有:
- 选择合适指令,生成性能最高的代码。
- 优化寄存器的分配,让频繁访问的变量,比如循环语句中的变量放到寄存器中,寄存器比内存快
- 在不改变运行结果下,对指令做重排序优化,从而充分运用CPU内部的多个功能部件的并行能力
本文参考:
编译原理实战课
编译原理之美
原文转载:http://www.shaoqun.com/a/485870.html
斑马物流:https://www.ikjzd.com/w/1316
adore:https://www.ikjzd.com/w/2202
声网agora:https://www.ikjzd.com/w/2176
编译:把源代码变成目标代码编译过程编译目标目标:把源代码变成目标代码1.如果源代码在操作系统上运行:目标代码就是"汇编代码"。再通过汇编和链接的过程形成可执行文件,然后通过加载器加载到操作系统执行。2.如果源代码在虚拟机(解释器)上运行:目标代码就是"解释器可以理解的中间形式的代码",比如字节码(中间代码)IR、AST语法树。编译过程可以分为这几个阶段,每个阶段做了一定的任务,层级的让下一个阶段进
insider:https://www.ikjzd.com/w/1786
prime:https://www.ikjzd.com/w/129
七天集训:教你做出一个漂亮的独立站!(二):https://www.ikjzd.com/home/96426
上海市博物馆推出"云看展"丰富市民文化生活:http://tour.shaoqun.com/a/75851.html
广州长隆三八节情侣多少钱?情侣三八妇女节去长隆价格?:http://tour.shaoqun.com/a/73674.html