Redis 集群演进探讨和总结
Redis为什么需要集群?
首先Redis单实例主要有单点,容量有限,流量压力上限的问题。
Redis单点故障,可以通过主从复制replication,和自动故障转移sentinel哨兵机制。
但Redis单Master实例提供读写服务,仍然有容量和压力问题,因此需要数据分区,构建多个Master实例同时提供读写服务(不仅限于从replica节点提供读服务)。
那么就需要一定的机制保证数据分区。这样能充分把容量分摊到多台计算机,或能充分利用多核计算机的性能。
并且数据在各个主Master节点间不能混乱,当然最好还能支持在线数据热迁移的特性。
探讨数据分区方案

针对数据分区,一般来说,分为两个大类:
- 逻辑拆分:
逻辑上能拆分,比如 Redis 中的 M1 节点 存储 A服务需要的业务数据,而 Redis 中的 M2 节点存储 B服务需要的业务数据。 - 数据分区:
当逻辑上不能拆分,那么只能按数据来拆分,需要保证客户端读和写数据一致。
因此需要一个高效快速的数据结构来路由对应的Master节点。
最容易想到的就是类比 Java 中的HashMap, 采用 哈希算法,快速找到,快速设置。
这里有四种方式,分别是固定取模,随机,哈希一致性,哈希槽。
固定取模
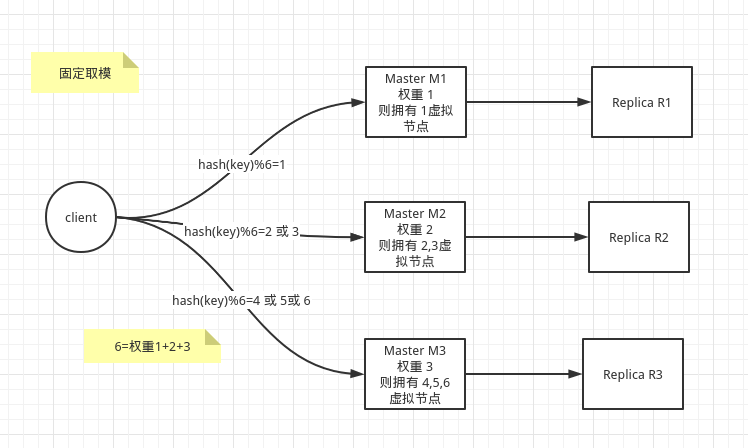
假设有三个 Master,配置IP 和权重如下:
| Real Server IP | weight |
|---|---|
| 10.0.2.21 | 1 |
| 10.0.2.22 | 2 |
| 10.0.2.23 | 3 |
那么会根据每一个real Server 及其权重虚拟出对应权重 weight 个的虚拟vritual server节点,映射关系会是:
| Real Server IP | virtual server |
|---|---|
| 10.0.2.21 | 1 |
| 10.0.2.22 | 2,3 |
| 10.0.2.23 | 4,5,6 |
一个 key 存储在那个虚拟vritual server节点,通过哈希hash算法:
virtual_server_index = hash(key) % (total_virtual_weight)假设某个key,它的 hash 值是 10,那么以上: 10%6=4,将落到 10.0.2.23 这个真实的 Master上。
- 缺点
因为取模的模数是固定的,当新增或删除 master节点时,所有的数据几乎要全部洗牌,几乎需要重新迁移数据(而且相当麻烦),无法做到在线数据热迁移。
意味着Redis在此种用法下,只能当缓存,不能当存储数据库!
随机
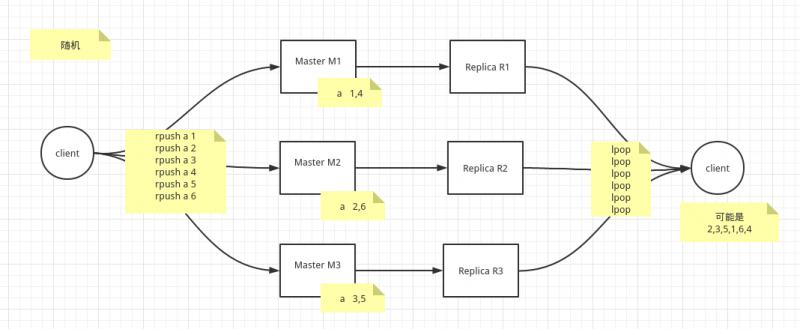
随机选取一个存储和访问。
一般结合 list,用于非顺序性要求的消息队列场景。
- 缺点:
使用场景比较单一。
并且由于随机性问题,导致持久化存在不可靠性。Redis在此种用法下,也只能当缓存,不能当存储数据库!
一致性哈希
一致性哈希算法(Consistent Hashing)最早在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。
简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下: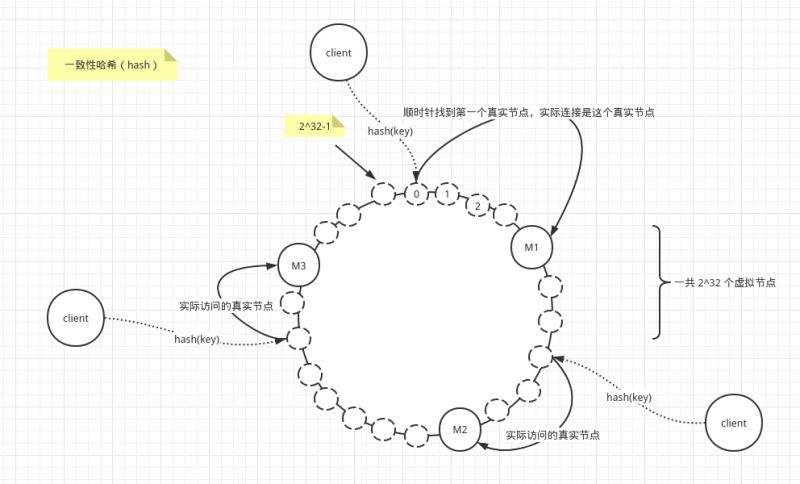
1.有一个HASH环,环上每个节点都是一个自然数,从0开始顺时针递增,直到2^32-1,最后回到0
2.真实节点 M1 M2 M3 通过 hash(IP 或主机名)确定在哈希环上的位置
3.当客户端请求时,首先 hash(key) 确定在哈希环上的位置,然后顺时针往后找,找到的第一个真实节点,就是客户端需要请求访问的真实主机
优点:
哈希一致性其实是对固定取模的一种优化。
(1)扩展性:当增加节点时,只会影响顺时针的真实节点(此部分数据比较难迁移),而不是影响全部的节点。
(2)容错性:当节点宕机或删除节点时,只会影响逆时针的真实节点,而不是影响全部的节点。
(3)平衡性:当哈希算法的节点过少时,会可能造成某些服务器的数据存储较多,而另外一些存储较少,造成数据倾斜,当节点足够多时,这种现象得以缓解。
因此虚拟节点个数较大的时候,数据的平衡性得以保证。缺点:
因为当增删节点时,需要重新计算受影响部分的节点中的key全部找出来,才能迁移,这个很麻烦!!!
Redis在此种用法下,也只能当缓存,不能当存储数据库!
哈希槽(PreSharding,预先分片)
这个跟哈希一致性很相似。
区别在于,它预先分配好真实节点管理的哈希槽(slot),并存储管理起来,我们可以预先知道哪个master主机拥有哪些哈希槽(slot),这里总数是16384。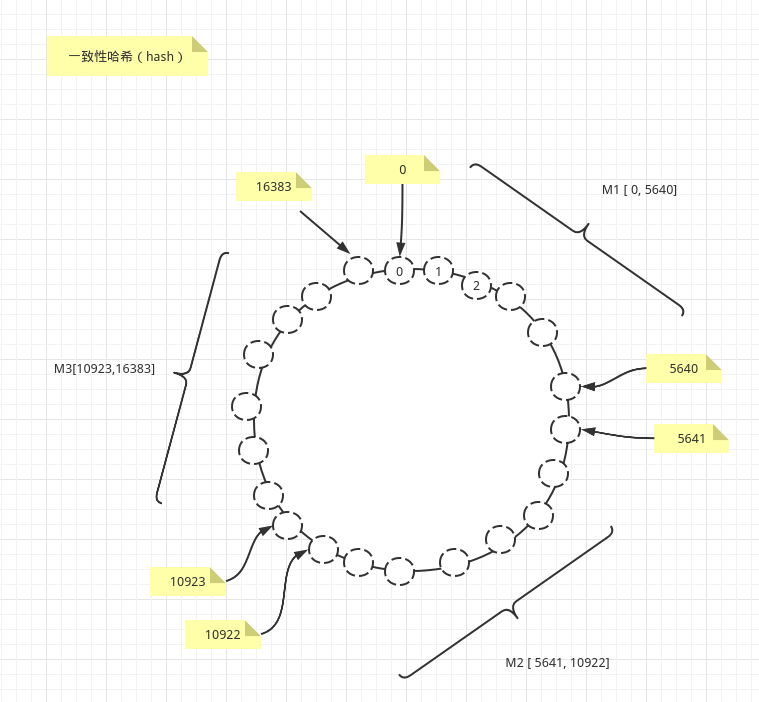
127.0.0.1:7001> cluster nodes2aaf59558f1b9f493a946a695e51711eb03d15f9 127.0.0.1:7002@17002 master - 0 1590126183862 2 connected 5461-109226439c3e9468fd2c545a63b3b9bfe658c5fc14287 127.0.0.1:7003@17003 master - 0 1590126181856 3 connected 10923-16383340d985880c23de9816226dff5fd903322e44313 127.0.0.1:7001@17001 myself,master - 0 1590126182000 1 connected 0-5460我们可以清晰看到Redis Cluster中的每一个master节点管理的哈希槽。
比如 127.0.0.1:7001 拥有哈希槽 0-5460, 127.0.0.1:7002 拥有哈希槽 5461-10922, 127.0.0.1:7003 拥有哈希槽 10923-16383。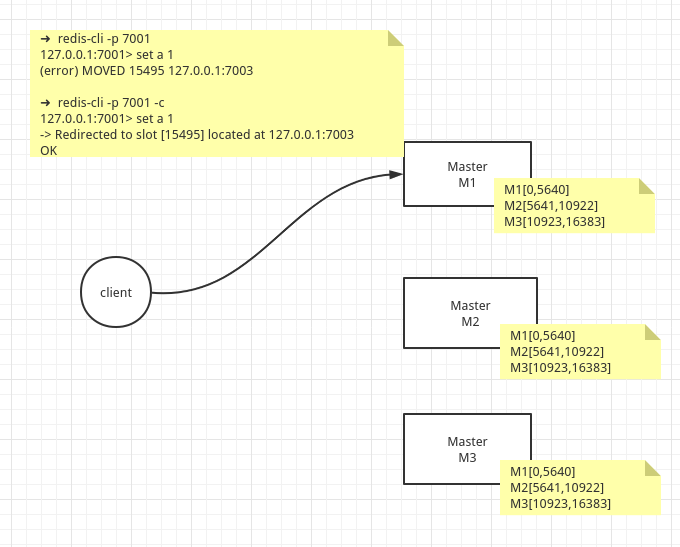
➜ redis-cli -p 7001 127.0.0.1:7001> set a 1(error) MOVED 15495 127.0.0.1:7003➜ redis-cli -p 7001 -c127.0.0.1:7001> set a 1-> Redirected to slot [15495] located at 127.0.0.1:7003OK我们看到的是master节点在 Redis Cluster中的实现时,都存有所有的路由信息。
当客户端的key 经过hash运算,发送slot 槽位不在本节点的时候。
(1)如果是非集群方式连接,则直接报告错误给client,告诉它应该访问集群中那个IP的master主机。
(2)如果是集群方式连接,则将客户端重定向到正确的节点上。
注意这里并不是127.0.0.1:7001 帮client去连接127.0.0.1:7003获取数据的,而是将客户端请求重定向了。
优点:
继承并增强一致性哈希的容错性,扩展性,以及平衡性。
Redis在此种用法下,可以当缓存,也能当存储数据库!这里Redis给出更详细的说明:https://redis.io/topics/partitioning
具体方案
以下列表为按照出现的先后顺序排列:
| 方案 | 描述 | 数据分区支持策略 | 分布式 |在线数据热迁移 |
|--|--|--|
| twemproxy | twitter 开源的redis代理中间件,不修改redis源码 https://github.com/twitter/twemproxy | 存在modula(固定取模)、 random (随机)、ketama(哈希一致性)三种可选的配置 | 本身是单点的,可以通过keepalived等保证高可用 | 不支持,无法平滑地扩容/缩容 |
|Redis Cluster | 官方提供的集群方案 | 采用预先分片(PreSharding),即哈希槽方式,存储在每一个master节点上 | 没有proxy代理层,客户端可以连接集群中的任意master节点 | 提供客户端命令redis-cli --cluster reshard ip port按哈希槽迁移指定节点的数据 |
| codis | 豌豆荚开源的redis代理中间件,修改了redis源码 https://github.com/CodisLabs/codis | 采用预先分片(PreSharding),即哈希槽方式,存储在ZooKeeper上 | 集群部署,部署相对复杂 | 支持数据热迁移 |
- Redis Cluster :一般生产环境量不大,且采用
Spring提供的RedisTemplate之类封装好的 fat client ,可以采用 - redis6.0后,官方也推出Redis Cluster的proxy方案 (https://github.com/RedisLabs/redis-cluster-proxy),只是尚为新,且处于beta阶段(2020.5处于1.0beta版本),不成熟。但未来可期,毕竟是官方支持的。
- 目前如果生产环境量大,但尚无研发能力,可以选用 codis
@SvenAugustus(https://www.flysium.xyz/)
更多请关注微信公众号【编程不离宗】,专注于分享服务器开发与编程相关的技术干货:

No comments:
Post a Comment